

Optimización de una cámara de bajo costo para visión artificial Deja un comentario
En este artículo de análisis profundo, el especialista en optimización del rendimiento Larry Bank (también conocido como The Performance Whisperer ) echa un vistazo al trabajo que hizo para el equipo de Arduino en la última versión de la biblioteca Arduino_OV767x.

Arduino anunció recientemente una actualización de la biblioteca de cámaras Arduino_OV767x que permite ejecutar visión artificial usando TensorFlow Lite Micro en su [19459013 ] Placa Arduino Nano 33 BLE .
Si solo quieres probar esto y ejecutar el aprendizaje automático en Arduino, puedes saltar al tutorial del proyecto .
El resto de este artículo analizará algunos de los trabajos de optimización de nivel inferior que hicieron posible todo esto. Hay opciones de mayor rendimiento orientadas a la industria, como el Arduino Portenta disponible para visión artificial, pero el Arduino Nano 33 BLE tiene un rendimiento suficiente con el soporte TensorFlow Lite Micro listo en el IDE de Arduino. Combinado con un módulo OV767x, es una solución de visión artificial de bajo costo para aplicaciones de menor velocidad de fotogramas como el ejemplo de detección de personas en TensorFlow Lite Micro.
Necesidad de velocidad
Las optimizaciones recientes realizadas por Google y Arm en la biblioteca CMSIS-NN también mejoraron la velocidad de inferencia de TensorFlow Lite Micro en más de 16 veces y, como consecuencia, redujeron el tiempo de inferencia de 19 segundos a solo 1,2 segundos en las placas Arduino Nano 33 BLE. Al seleccionar el ejemplo person_detection en la biblioteca Arduino_TensorFlowLite, automáticamente incluirá CMSIS-NN debajo y se beneficiará de estas optimizaciones. ¡La única diferencia que debería ver es que se ejecuta mucho más rápido!
La biblioteca CMSIS-NN proporciona implementaciones de kernel de red neuronal optimizadas para todos los procesadores Arm’s Cortex-M, desde Cortex-M0 a Cortex-M55. La biblioteca utiliza las capacidades del procesador, como las extensiones DSP y M-Profile Vector ( MVE ), para permitir el mejor rendimiento posible.
La placa Arduino Nano 33 BLE funciona con Arm Cortex-M4, que admite extensiones DSP. Eso permitirá que los kernels optimizados realicen múltiples operaciones en un ciclo usando instrucciones SIMD (Single Instruction Multiple Data). Otra técnica de optimización utilizada por la biblioteca CMSIS-NN es el desenrollado de bucles. Estas técnicas combinadas nos darán el siguiente ejemplo donde la instrucción SIMD, SMLAD (Signed Multiply with Addition), se usa junto con el desenrollado de bucle para realizar una multiplicación de matrices y = a * b, donde
a = [1,2]
y
b = [3,5
4,6]
a, b son valores de 8 bits e y es un valor de 32 bits. Con C normal, el código se vería así:
para (i = 0; i <2; ++ i) para (j = 0; j <2; ++ j) y [i] + = a [j] * b [j] [i]
Sin embargo, al usar el desenrollado de bucle y las instrucciones SIMD, el bucle terminará luciendo así:
a_operand = a [0] | a [1] << 16 // coloca un [0], un [1] en una variable para (i = 0; i <2; ++ i) b_operand = b [0] [i] | b [1] [i] << 16 // viceversa para b y [i] = __SMLAD (a_operand, b_operand, y [i])
Este código guardará ciclos debido a
- menos comprobaciones de bucle for
- __SMLAD realiza dos multiplicaciones y acumulaciones en un ciclo
Este es un ejemplo simplificado de cómo dos de las técnicas de optimización CMSIS-NN son usados.
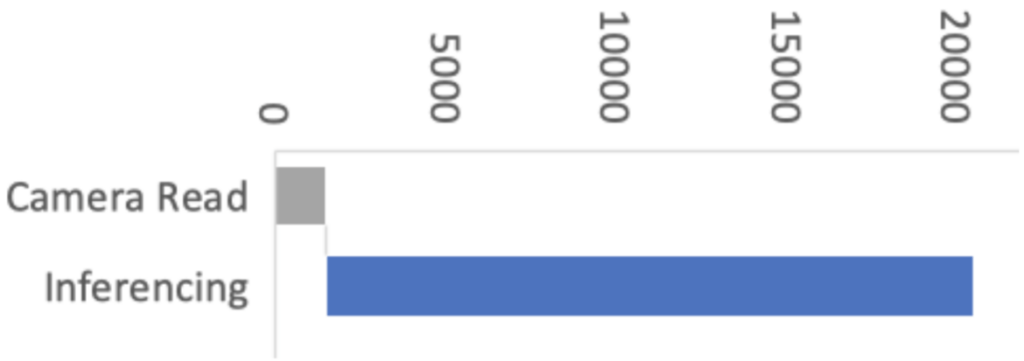
[19459030 ] Figura 2: Rendimiento con optimizaciones CMSIS-NN
Esta mejora significa que las etapas de adquisición de imágenes y preprocesamiento ahora tienen un impacto proporcionalmente mayor en el rendimiento de la visión artificial. Entonces, en Arduino, nuestro objetivo era mejorar el rendimiento general de la inferencia de visión artificial en Arduino Nano BLE sense optimizando la biblioteca Arduino_OV767X mientras se mantiene la misma API de biblioteca, usabilidad y estabilidad.
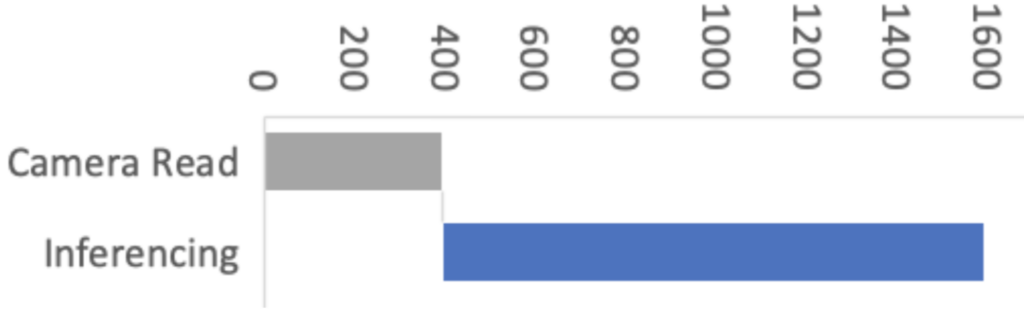
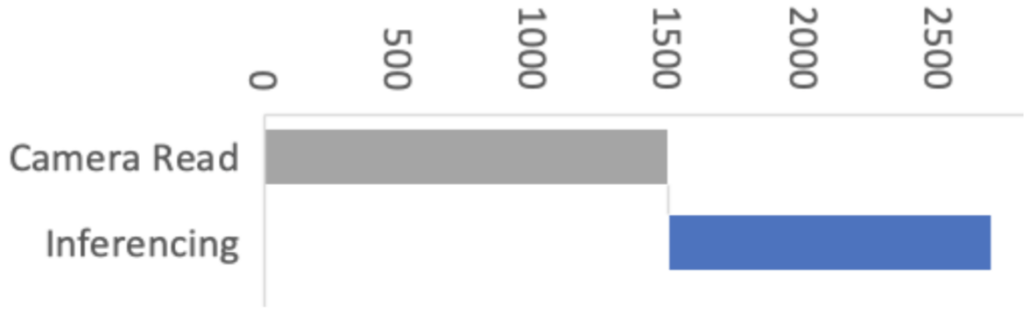
Para esto, contamos con la ayuda de Larry Bank, que se especializa en optimización de software integrado. El trabajo de Larry redujo la lectura de la imagen de la cámara de 1500 ms a solo 393 ms para una imagen QCIF (176 × 144 píxeles). ¡Fue una gran mejora!
Echemos un vistazo a cómo Larry abordó la optimización de la biblioteca de la cámara y cómo algunas de estas técnicas pueden aplicarse a su código Arduino en general.
Rendimiento optimizando el código Arduino
Rara vez es práctico o necesario optimizar cada línea de código que escribe. De hecho, existen muy buenas razones para priorizar el código legible y mantenible. Ser legible y optimizado no tiene por qué ser necesariamente excluyentes. Sin embargo, los sistemas integrados tienen recursos limitados y, cuando las aplicaciones exigen más rendimiento, es posible que deban hacerse algunas concesiones. A veces es necesario reestructurar algoritmos, prestar atención al comportamiento del compilador o incluso analizar el tiempo de las instrucciones del código de máquina para sacar el máximo provecho de un microcontrolador. En algunos casos, esto puede hacer que el código sea menos legible, pero la belleza de una biblioteca Arduino es que esto se puede abstraer (ocultar) del código de boceto del usuario debajo de las API de funciones de biblioteca más limpias.
¿Qué hace “Camera.readFrame”?

Conectamos una cámara al Arduino. La biblioteca Arduino_OV767X configura la cámara y nos permite transferir los datos de la imagen sin procesar de la cámara a la memoria Arduino Nano BLE. La configuración de resolución más pequeña, QCIF, es de 176 x 144 píxeles. Cada píxel está codificado en 2 bytes. Por lo tanto, necesitamos transferir al menos 50688 bytes (176 x 144 x 2) cada vez que capturamos una imagen con Camera.readFrame . Debido a que la función realiza una operación de lectura de bytes más de 50 mil veces por fotograma, la forma en que se implementa tiene un gran impacto en el rendimiento. Así que echemos un vistazo a cómo podemos conectar la cámara al Arduino de la manera más eficiente y leer un byte de datos.
Filosofía
Tiendo a ver el mundo del código a través de la “lente” de la optimización. No estoy abogando por que todos compartan mi obsesión por la optimización. Sin embargo, cuando sea necesario, es útil comprender los detalles del hardware y la CPU de destino. Lo que me encuentro a menudo con mis clientes es que su código implementa su algoritmo de forma ordenada y es muy legible, pero no es necesariamente “amigable con el rendimiento” para la máquina de destino. Supongo que esto se debe a que la mayoría de las personas ven el código desde un enfoque de arriba hacia abajo: piensan en términos de matemáticas abstractas y cómo procesar los datos. Mi historial de trabajar con máquinas muy humildes y luego convertir eso en una carrera ha cambiado esa narrativa de cabeza. Veo el software de abajo hacia arriba: pienso en cómo interactúan la memoria, las E / S y los registros de la CPU para mover y procesar los datos utilizados por el algoritmo. A menudo, es posible realizar mejoras drásticas en la velocidad de ejecución del código sin perder su legibilidad. Cuando su solución legible / mantenible aún no es lo suficientemente rápida, la siguiente fase es lo que yo llamo ‘uglificación’. Esto implica escribir código que aproveche las características específicas de la CPU y casi siempre es más difícil de seguir (al menos al principio ¡vistazo!).
Metodología de optimización
La optimización es un proceso iterativo. Normalmente trabajo en este orden:
- Probar supuestos en el algoritmo (a veces requiere rastrear los datos)
- Realizar cambios inocuos en la lógica para adaptarse mejor a la CPU (por ejemplo, cambiar el módulo a lógico AND)
- Aplanar la jerarquía o simplificar clases / estructuras demasiado anidadas
- Pruebe las rutas lentas / rápidas (también conocidas como estadísticas de los datos, por ejemplo, ¿el 99% de los datos entrantes es 0?)
- Volver al autor (s) y cuestionar sus decisiones sobre precisión / almacenamiento de datos
- Hacer que el código sea más adecuado para la arquitectura de destino (por ejemplo, registros de CPU de 32 vs 64 bits)
- Si es necesario (y permitido por el cliente) usa intrínsecos u otras características específicas de la CPU
- Vuelve atrás y prueba todas las suposiciones nuevamente
Si deseas investigar más este tema, he escrito una presentación más detallada sobre Escritura de código C ++ de rendimiento .
Según el tamaño del proyecto, a veces es difícil saber por dónde empezar si hay demasiadas partes móviles. Si hay un generador de perfiles disponible, puede ayudar a reducir la búsqueda de los “puntos calientes” o funciones que están tomando la mayor parte del tiempo para hacer su trabajo. Si no hay un generador de perfiles disponible, generalmente usaré una función de tiempo como micros () para leer el contador de ticks actual para medir la velocidad de ejecución en diferentes partes del código. Aquí hay un ejemplo de medición del tiempo de ejecución absoluto en Arduino:
long lTime; lTime = micros (); iTime = micros () - lTime; Serial.printf (“Tiempo para ejecutar xxx =% d microsegundos n”, (int) lTime);
También utilicé un generador de perfiles para mi trabajo de optimización con OpenMV . Modifiqué el código C incorporado para que se ejecutara como una aplicación de línea de comandos de MacOS para hacer uso del excelente generador de perfiles XCode Instruments . Al hacer eso, es importante comprender cuán diferente se ejecuta el código en una PC en comparación con el código integrado; esto se debe principalmente a la velocidad de la CPU en comparación con la velocidad de la memoria.
Pines, GPIO y PORT
Una de las características más poderosas de la plataforma Arduino es que presenta una API consistente para el programador para acceder a características de hardware y software que, en realidad, pueden variar mucho entre diferentes arquitecturas de destino. Por ejemplo, las características que se encuentran en común en la mayoría de los dispositivos integrados como pines GPIO, I2C, SPI, FLASH, EEPROM, RAM, etc.tienen muchas implementaciones diversas y requieren un código muy diferente para inicializarlas y acceder a ellas.
Veamos el primero de nuestra lista, GPIO ( G eneral P urpose I nput / O pines de salida). En el Arduino Uno original (AVR MCU), las líneas GPIO están organizadas en grupos de 8 bits por “PUERTO” (es una CPU de 8 bits después de todo) y cada puerto tiene un registro de dirección de datos (determina si está configurado para entrada o salida), un registro de lectura y un registro de escritura. Las placas Arduino más nuevas están todas construidas alrededor de varios microcontroladores Arm Cortex-M. Estas MCU tienen pines GPIO dispuestos en grupos de 32 bits por “PUERTO” (hmm, es una CPU de 32 bits, me pregunto si esa es la razón). Tienen un conjunto similar de mecanismos de control, pero agregan un giro: incluyen registros a bits específicos SET o CLR sin perturbar los otros bits del puerto (por ejemplo, puerto-> CLR = 1; borrará el bit 0 de GPIO de ese puerto). Desde el punto de vista del programador, Arduino presenta un conjunto consistente de funciones para acceder a estos pines en estas diversas plataformas (enlaces en los que se puede hacer clic a continuación para las definiciones de funciones en Arduino.cc):
(pin, modo);
(pin);
(pin, valor);
Para mí, esta es la idea más poderosa de Arduino. Puedo compilar e implementar mi código en un AVR, un Cortex-M, ESP8266 o un ESP32 y no tengo que cambiar una sola línea de código ni mantener múltiples scripts de compilación. De hecho, en mi trabajo diario (tanto hobby como profesional), estoy constantemente probando mi código en esas 4 plataformas. Por ejemplo, mi biblioteca de pantallas LCD / OLED ( OneBitDisplay ) puede controlar varias pantallas LCD y OLED monocromas y el mismo código se ejecuta en todas las placas Arduino e incluso se puede construir en Linux.
Una desventaja de que estas funciones “contenedoras” oculten los detalles de la implementación subyacente es que el rendimiento puede verse afectado. Para la mayoría de los proyectos no es un problema, pero cuando necesita obtener cada gramo de velocidad de su código, puede marcar una gran diferencia.
Captura de datos de la cámara
Uno de los mayores desafíos de este proyecto fue que la biblioteca original OV7670 solo podía ejecutarse a menos de 1 fotograma por segundo (FPS) cuando se hablaba con el Nano 33. La razón de la baja velocidad de datos es que el Nano 33 no expone ningún hardware que pueda capturar directamente los datos de la imagen en paralelo, por lo que debe hacerse ‘manualmente’ probando las señales de sincronización y leyendo los bits de datos a través de pines GPIO (por ejemplo, digitalRead) usando bucles de software. Las funciones de pin de Arduino (digitalRead, digitalWrite) en realidad contienen una gran cantidad de código que verifica que el número de pin sea válido, utiliza una tabla de búsqueda para convertir el número de pin en la dirección del puerto de E / S y el valor de bit e incluso puede deshabilitar las interrupciones antes de leer o cambiar el estado del pin. Si usáramos la función digitalRead para una aplicación como esta, limitaría la velocidad de captura de datos para que sea demasiado lenta para operar la cámara. Verá esto más abajo cuando examinemos el código real utilizado para capturar los datos.
Primero, una revisión rápida del módulo de cámara OV7670: según su hoja de datos, es capaz de capturar una imagen en color VGA (640 × 480) a hasta 30 FPS. El kit utilizado para este proyecto tiene la cámara montada en un pequeño PCB y presenta un bus de datos paralelo de 8 bits y varias señales de sincronización.

Requiere un “reloj maestro” externo (MCLK en la foto) para impulsar su máquina de estado interno que se utiliza para generar todas las demás señales de temporización. El Nano 33 puede proporcionar esta fuente de reloj externa utilizando su reloj I2S. La biblioteca OV767X establece este reloj maestro en 16Mhz (la cámara puede manejar hasta 48Mhz) y luego hay un conjunto de registros de configuración para dividir este valor para llegar a la velocidad de cuadros deseada. Solo están disponibles algunas velocidades de fotogramas posibles (1, 5, 10, 15, 20 y 30 FPS).

Arriba está uno de los diagramas de tiempo de la hoja de datos del OV7670. Este dibujo en particular muestra la sincronización de los datos para cada byte recibido a lo largo de cada fila de imágenes. La señal HREF se usa para señalar el inicio y el final de una fila y luego cada byte se sincroniza con la señal PCLK. El código de la biblioteca original leyó cada bit (D0-D7) en un bucle y los combinó para formar cada byte de datos. Los datos de la imagen llegan rápidamente, por lo que tenemos muy poco tiempo para leer cada byte. Ensamblarlos poco a poco no es muy eficiente. Quizás esté pensando que no es un problema tan difícil de resolver en el Nano 33. Después de todo, tiene 22 pines GPIO y el Cortex-M en su interior tiene puertos GPIO de 32 bits de ancho, así que simplemente conecte los bits de datos secuencialmente y podrá leer los 8 bits de datos de una sola vez, luego Misión cumplida ™ . Si las cosas fueran tan fáciles. El Nano 33 tiene muchos pines GPIO, ¡pero no hay una secuencia continua de 8 bits disponible usando ninguno de los pines! Supongo que el código original lo hizo poco a poco porque no parecía que hubiera una alternativa mejor. En el diagrama de distribución de pines a continuación, observe los números P0.xx y P1.xx. Estos son los números de puerto 0 y 1 bit Cortex-M GPIO (otros procesadores Cortex-M los etiquetarían como PA y PB).
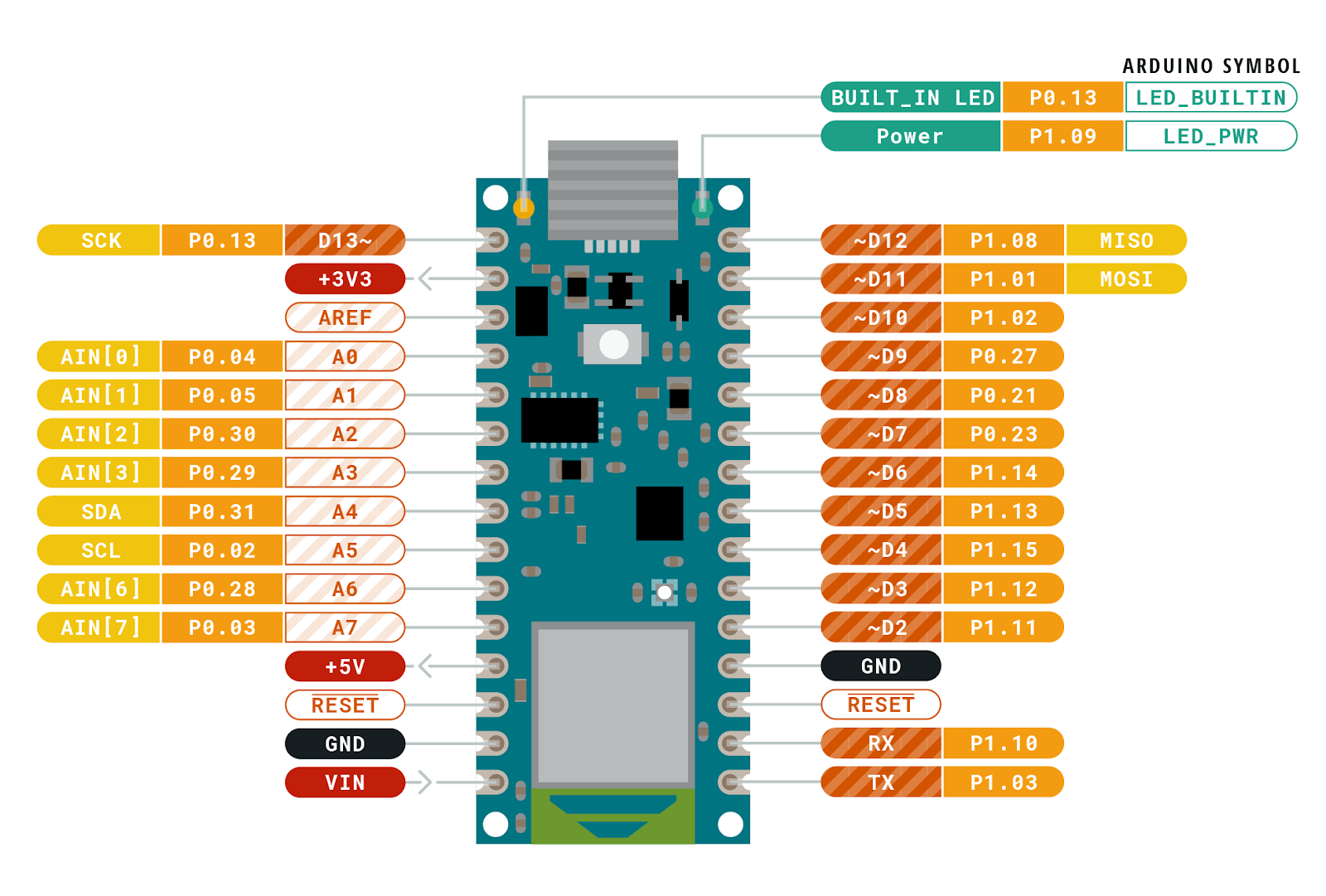
No iba a permitir que este pequeño bache en el camino me impidiera hacer uso del paralelismo de bits. Si observa detenidamente las posiciones de los bits, la mejor ejecución continua que podemos obtener es de 6 bits seguidos con P1.10 a P1.15. No es posible leer los 8 bits de datos de una sola vez … ¿o no? Si conectamos D0 / D1 de la cámara a P1.02 / P1.03 y D2-D7 a P1.10-P1.15, podemos hacer una sola lectura de 32 bits desde el puerto P1 y obtener los 8 bits de una sola vez . Los bits están en orden, pero tendrán un espacio entre D1 y D2 (P1.04 a P1.09). Afortunadamente, la CPU Arm tiene lo que se llama una palanca de cambios de barril . También tiene un conjunto de instrucciones inteligentes que permite que los datos se transfieran “gratis” al mismo tiempo que la instrucción está haciendo otra cosa. Veamos cómo y por qué cambié el código:
Original:
uint8_t en = 0;
para (int k = 0; k <8; k ++) {
bitWrite (in, k, (* _dataPorts [k] & _dataMasks [k])! = 0);
}
Optimizado:
uint32_t en = puerto-> IN; // lee todos los bits en paralelo en >> = 2; // coloca los bits 0 y 1 en la "parte inferior" del Registrarse en & = 0x3f03; // aislar los 8 bits que nos importan en | = (en >> 6); // combina los 6 bits superiores y los 2 inferiores
Análisis de código
Si no está interesado en los detalles esenciales de los cambios de código que hice, puede omitir esta sección e ir directamente a los resultados a continuación. Primero, veamos lo que hizo el código original. Cuando lo miré por primera vez, no reconocí bitWrite ; aparentemente no es una macro de manipulación de bits de Arduino muy conocida; se define como:
#define bitWrite (valor, bit, bitvalue) (bitvalue? bitSet (valor, bit): bitClear (valor, bit))
Esta macro se escribió con la intención de ser utilizada en puertos GPIO (la variable valor ) donde el estado lógico de bitvalue se convertiría en una sola escritura de un 0 o 1 al bit apropiado. Tiene menos sentido usarlo en una variable regular porque inserta una rama para cambiar entre los dos resultados posibles. Para la tarea en cuestión, no es necesario usar bitClear () en la variable en , ya que ya está inicializada en 0 antes del inicio de cada bucle de bytes. Una mejor opción sería:
if (* _dataPorts [k] & _dataMasks [k]) in | = (1 << k);
Las matrices _dataPorts [] y _dataMasks [] contienen las direcciones de puerto GPIO mapeadas en memoria y máscaras de bits para acceder directamente a los pines GPIO (sin pasar por digitalRead). Así que aquí hay una reproducción por reproducción de lo que estaba haciendo el código original:
- Establecer en 0
- Establecer k en 0
- Leer la dirección del puerto GPIO de _dataPorts [] en el índice k
- Leer la máscara de bits del puerto GPIO de _dataMasks [] en el índice k
- Leer datos de 32 bits de la dirección del puerto GPIO
- Lógico Y los datos con la máscara
- Desplazamiento 1 dejado por k bits para preparar bitClear y bitSet
- Compare el resultado de AND con cero
- Bifurque al código bitSet () si es verdadero o use bitClear () si es falso
- bitClear o bitSet dependiendo del resultado
- Incremento de la variable de bucle k
- Compare k con el valor constante 8
- Bifurque si es menor, vuelva al paso 3
- Repita los pasos 3 a 13, 8 veces
- Almacenar el byte en la matriz de datos (no se muestra arriba)
El nuevo código no lo siguiente:
- Leer los datos de 32 bits de la dirección del puerto GPIO
- Desplazarlo a la derecha 2 bits
- Lógico Y (enmascarar) los 8 bits que nos interesan [19459026 ]
- Cambie y OR los resultados para formar 8 bits continuos
- Almacene el byte en la matriz de datos (no se muestra arriba)
Cada uno de los pasos enumerados arriba básicamente se traduce en una sola instrucción Arm. Si asumimos que cada instrucción toma aproximadamente la misma cantidad de tiempo para ejecutarse (mayormente cierto en Cortex-M), entonces lo antiguo frente a lo nuevo son 91 frente a 5 instrucciones para capturar cada byte de datos de la cámara, ¡una mejora de 18x! Si capturamos un fotograma QVGA (320x240x2 = 153600 bytes), eso se convierte en muchos millones de instrucciones adicionales s.
Resultados
El código de captura de bytes optimizado se traduce en instrucciones de 5 brazos y permite que el bucle de captura maneje ahora una configuración de 5 FPS en lugar de 1 FPS. Los números de FPS no parecen ser exactos, pero el tiempo de captura original (QVGA a 1 FPS) fue de 1,5 segundos, mientras que el nuevo tiempo de captura cuando se establece en 5 FPS es de 0,393 segundos. Probé 10 FPS, pero readFrame () no lee los datos correctamente a esa velocidad. No tengo un osciloscopio a la mano para sondear las señales y ver por qué está fallando. El código puede ser lo suficientemente rápido ahora (creo que lo es), pero las señales de sincronización pueden volverse demasiado inestables a esa velocidad. Dejaré esto como un ejercicio para los lectores que tienen el equipo para ver qué sucede con las señales a 10 FPS.
Para el trabajo que hice en la biblioteca OV767X, creé un dispositivo de prueba para asegurarme de que los datos de la cámara se recibían correctamente. Para las aplicaciones de procesamiento de datos / ML, no es necesario hacer esto. El patrón de prueba de la cámara incorporada se puede utilizar para confirmar la integridad de los datos utilizando un CRC32.

Nota: Los marcos vienen uno inmediatamente después del otro. Si captura un fotograma y luego procesa un poco y luego intenta capturar otro fotograma, puede llegar a la mitad del siguiente cuando llame a readFrame (). Luego, el código esperará hasta la siguiente señal VSync, por lo que el tiempo de captura de la trama podría ser hasta 2 veces mayor que el tiempo de una sola trama.
Más sugerencias
Disfruto probando los límites del hardware integrado, especialmente cuando se trata de bits, bytes y píxeles. He escrito algunas entradas de blog que exploran los temas de velocidad y uso de energía si está interesado en aprender más al respecto.
Conclusión
- Los microcontroladores integrados disponibles en la actualidad son capaces de realizar trabajos que eran inimaginables hace apenas unos años.
- Las soluciones de aprendizaje automático optimizadas de Google y Edge Impulse pueden ejecutarse en tableros de bajo costo que funcionan con baterías (visión, vibración, audio, cualquier sensor que desee monitorear).
- Los entornos de programación Python y Arduino pueden probar la idea de su proyecto con poco esfuerzo.
- El software se puede escribir en un número infinito de formas para realizar la misma tarea, pero permanece una constante: TANSTATFC (no existe el código más rápido).
- Nunca asumas que el rendimiento que estás viendo es con lo que estás atrapado. Piense en las bibliotecas existentes y las API genéricas disponibles a través de bibliotecas y entornos de código abierto como punto de partida.
- Conocer un poco de información sobre la plataforma de destino puede ser útil, pero no es necesario leer la hoja de datos de MCU. En el código anterior, el concepto más amplio de puertos GPIO Arm Cortex-M de 32 bits fue suficiente para realizar la tarea sin conocer los detalles del hardware de E / S del nRF52.
- No tenga miedo de profundizar un poco más y probar todas las suposiciones.
- Si encuentra dificultades, la comunidad es grande y hay un montón de recursos disponibles. Pedir ayuda es un signo de fortaleza, no de debilidad.
Puede seguir cualquier respuesta a esta entrada a través del feed RSS 2.0 .
Puede dejar una respuesta o trackback desde su propio sitio.
Fuente: